今天要正式進入爬蟲啦~第一個練習是要去爬Google好手氣裡的圖片!
google好手氣在哪裡呢?其實就在平常其實就在平常在google首頁,中間有兩個方塊的右邊那個就是了!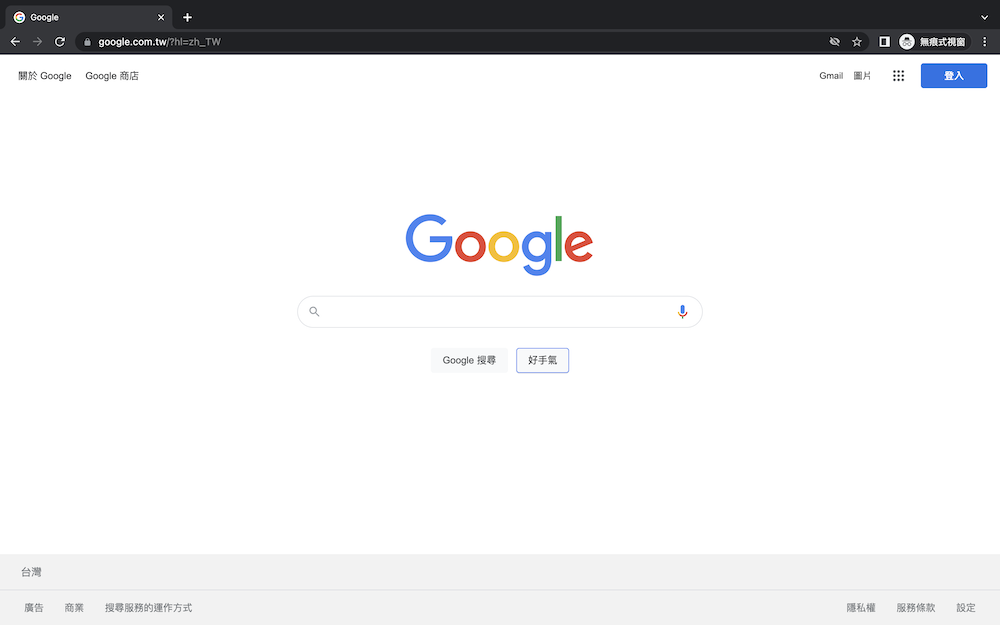
一開始先講一下爬蟲的SOP好了,它的目的是要幫你找到正確的網址。
先從第一步來,看到原始碼後可以知道這裡只有六張圖片,但我們想要的不只六張,所以要去找隱藏網址。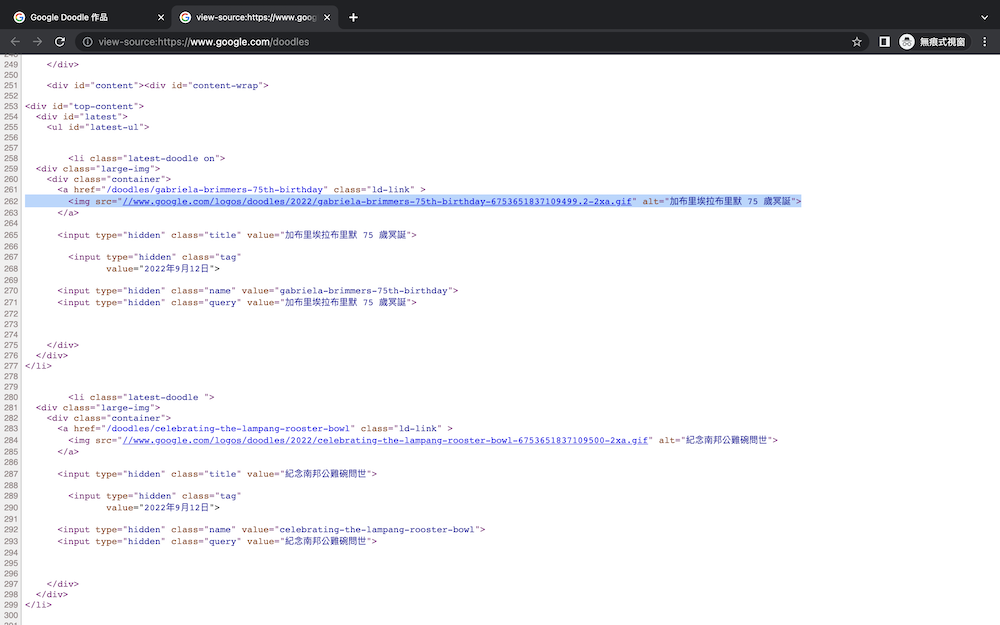
打開F12後,滑動頁面會發現,Name的部分跳出越來越多的資料,代表它跟google要到更多的圖片。隨便選擇一個月份,再點到Preview的地方就可以看到每張圖片的網址,要注意到的是它外面是用中括號括起來的代表是一個list,而最前面0123就是索引值,每一個元素都是一個字典,這就是JSON格式(list+dict)
接著要匯入爬蟲必備的requests函式庫,由於它是第三方的所以要事先下載。接著輸入你要爬的網址,要記得並不是輸入上方的網址列,而是F12裡月份點進去Headers的Gerenal網址。再來用requests裡的get()方法送出網址並得到回應,這裡response的是一種檔案類型而不是單純的值,所以是print不出東西的。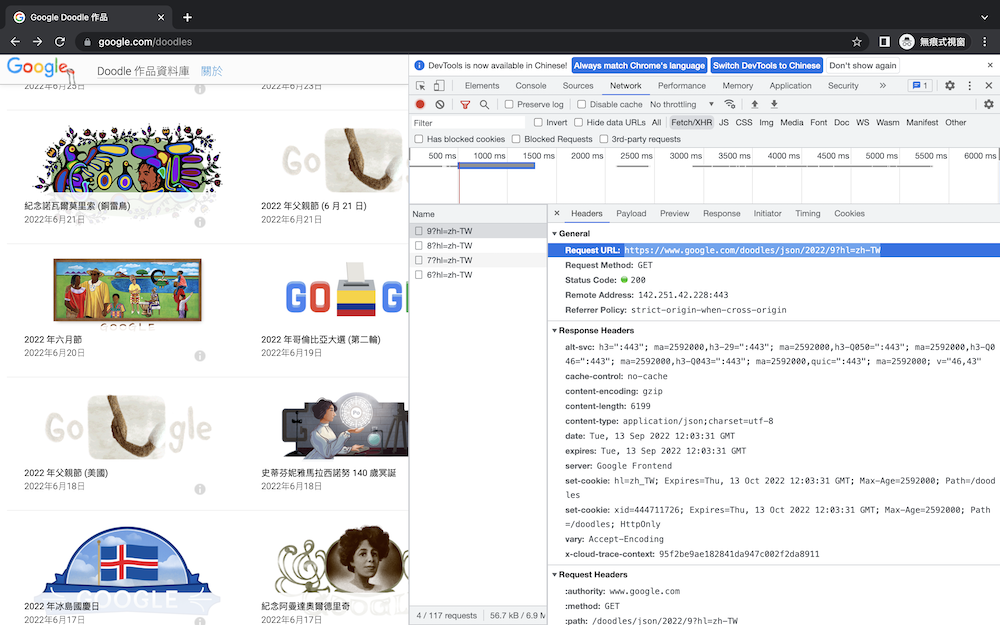
import requests
url = "https://www.google.com/doodles/json/2022/9?hl=zh-TW"
response = requests.get(url)
但我們希望拿到的資料是像網站上的一樣是list+dict,所以當拿到的資料型態不符合預期的時候,就是要來做型態轉換,可以直接用response.json將型態轉成json格式,不過必須原本就是這種格式不然會發生錯誤,但是既然要用這個功能,要記得import json函式庫,這個是Python內建的所以不需要像requests一樣另外先下載好。
import json
pics = response.json()
現在pics這個list裡面放的是一張一張的圖也是一個一個的字典,所以現在要做的第一個操作是把每一張圖的網址拿出來並下載它,既然要跑很多次當然就是用到迴圈。由於p的型態是字典,如果想取裡面的value(網址)就要呼叫它的key,也就是title這個欄位,第二個我需要高畫質版本的網址,不過可以看到它前面缺了https:,所以需要幫它補一下。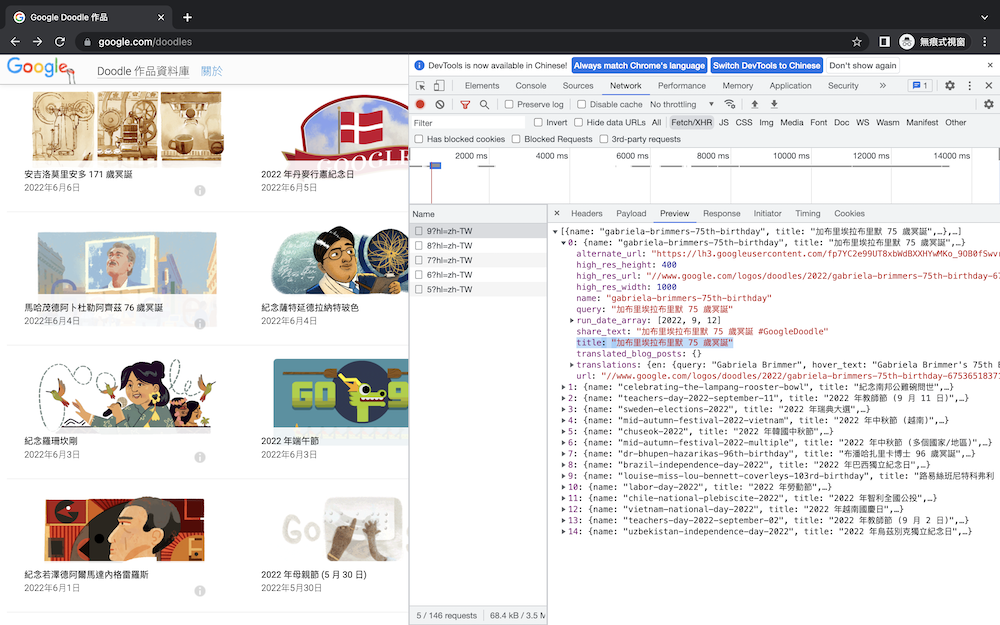
for p in pics: # p的型態是字典
print(p["title"]) # 列印圖片標題
imgurl = "https:" + p["high_res_url"] # 取得高畫質版本
print(imgurl)
print("-" * 30) # 最後印個分隔線
列出網址後總要下載到本地端嘛,存檔總會需要路徑而且最後的副檔名要是圖片檔(.gif/.png),可以發現剛剛輸出的高畫質版本的網址最後就有副檔名,所以就直接把網址的最後一個部分拆下來,可以用split()方法,用"/"當作分隔符號。
for p in pics:
print(p["title"])
imgurl = "https:" + p["high_res_url"]
print(imgurl)
fn = imgurl.split("/")[-1] # 把網址的最後一個部分拆下來
print("-" * 30) # 最後印個分隔線
這時候如果直接存檔,圖片檔是會存到和main.py同一層,這樣好亂,我想用一個資料夾把它們關起來。現在我要儲存的路徑會是dn/fn,資料夾下面的檔案的感覺,接著要記得再把網址送出才可以拿到一個一個圖片的網址,最後把圖片轉成二進制的資料寫進圖片檔裡。用with...as打開檔案的好處是不需要再寫f.close()關閉檔案,因為本身就已經有這個功能了。
dn = "doodles" # 創建一個資料夾
if not os.path.exists(dn): # 如果這個資料夾不存在
os.makedirs(dn) # 那就建立一個資料夾
for p in pics:
print(p["title"]) # 列印圖片標題
imgurl = "https:" + p["high_res_url"] # 取得高畫質版本
print(imgurl)
fn = imgurl.split("/")[-1] # 把網址的最後一個部分拆下來
totalfn = dn + "/" + fn
Simgurl = requests.get(imgurl, stream=True) # 再次把圖片網址送出
img = Simgurl.content # 把圖片轉成二進制的
with open(totalfn, "wb") as f:
f.write(img)
print("-" * 30) # 最後印個分隔線
import requests
import os # 所有跟作業系統有關的函示庫
import json # 內建的不需要額外下載
dn = "doodles"
if not os.path.exists(dn): # 如果這個資料夾不存在
os.makedirs(dn) # 那就建立一個資料夾
url = "https://www.google.com/doodles/json/2022/9?hl=zh-TW"
response = requests.get(url)
pics = response.json()
for p in pics:
print(p["title"]) # 列印圖片標題
imgurl = "https:" + p["high_res_url"] # 取得高畫質版本
print(imgurl)
fn = imgurl.split("/")[-1] # 把網址的最後一個部分拆下來
totalfn = dn + "/" + fn
Simgurl = requests.get(imgurl, stream=True) # 再次把圖片網址送出
img = Simgurl.content # 把圖片轉成二進制的
with open(totalfn, "wb") as f:
f.write(img)
print("-" * 30) # 最後印個分隔線


 iThome鐵人賽
iThome鐵人賽